Modèle d'architecture Hub and Spoke, pourquoi c'est efficace ?
Depuis que j'ai commencé à travaillé, ça fait maintenant quelques années. Ca fait drôle de dire ça alors que je travaille que depuis 13 ans, mais la techno et les outils évoluent tellement vite...
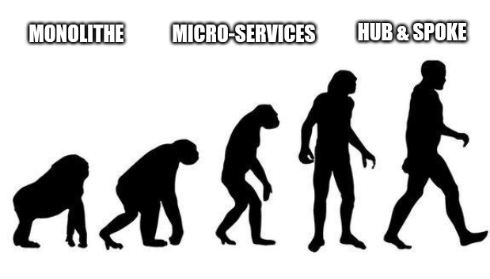
Au début, on ne jurait que par les monolithes, c'était efficace car tout le code se trouvait au même endroit.
Ca permettait de livrer au client un gros package à installer qui était auto porté.
De grands noms ont surfé pendant cette période, et tous les logiciels fonctionnaient de la même façon. CMS, ERP, CRM... Une fois rentré dedans, Impossible de bouger et d'aller ailleurs.
Puis l'ère des micro-services est arrivée. Changement de paradisme, on va essayer de découper le plus finement possible chaque partie de l'application, parfois jusqu'à des cas extrêmes. Moi même, j'ai pu expérimenter des services trop spécifiques au début, et qui ont grossit à devenir des usines. car il fallait prendre en compte les problématiques de bons nombres de services annexes. Les micro-services ont été aussi démocratisés grace aux systèmes de pipelines CICD. D'abord Jenkins, puis maintenant Github et Gitlab.
Et quand on cumule tous les micro-services en place, on arrive à l'inconvénient principal, la gestion de compatibilité entre services. Quand une équipe a d'autres priorités que de MAJ un service, les autres vont essayer de contourner, et c'est l'effet domino.
Vient donc l'avènement du pattern Hub and Spoke, qui, sur le papier semble pour l'instant tenir la cadence. En même temps on a rien inventé non plus, nous les techos, La roue qui exprime parfaitement ce principe était là bien avant nous. Un moyeu central "Hub" qui fait travailler les "Spoke" pour avancer.
Comprendre le Pattern Hub-and-Spoke
Le modèle Hub-and-Spoke repose sur une idée simple : un "hub" central qui gère les ressources critiques (comme la sécurité, la connectivité ou le monitoring) et des "spokes" qui représentent des réseaux ou environnements autonomes. Dans nos projets on-premise, le hub était souvent une infrastructure centrale unifiée et unique, tandis que les spokes correspondaient à un environnement séparé..
L'objectif est de simplifier la gestion tout en maintenant une bonne isolation entre les différentes parties de l'infrastructure. ça permet aussi de réduire les couts de maintenance et infrastructure. ça semble simple en théorie, mais en pratique, il y a des subtilités importantes.
Ce qu'on a gagné en plus-value
1. Centralisation des Services Critiques
Avec le hub central, nous avons pu mutualiser des services comme les firewalls, les systèmes de monitoring (Zabbix, Prometheus), et notre solution de sauvegarde (Veeam). ça a considérablement réduit la duplication des services, donc moins de maj à faire, et des coûts. On y a aussi mis les passerelles NAT pour contrôler les sorties internet ainsi notre OIDC général Keycloak pour la gestion des identités.
2. Amélioration de la Sécurité
Dans un environnement VMWare, on a utilisé le hub pour implémenter une segmentation stricte entre les spokes. ça a permis d'isoler les environnements de production des environnements de test, tout en partageant certains services critiques comme les bases de données ou les plateformes d'authentification.
Cette isolation a été un point clé pour répondre aux exigences de conformité réglementaire, comme celles liées à la RGPD, et la future NIS2 qui arrive.
3. Flexibilité pour les Spokes
Chaque spoke peut être configuré indépendamment selon les besoins spécifiques de son environnement. Chaque équipe dispose de son propre spoke, qui peut être un VPC ou un sous-réseau dédié. Les bonnes pratiques voudraient :
Les spoke ne communiquent entre eux que via le hub. En théorie, on peut faire un peering entre les spokes, mais on perd l'utilité de la segmentation.
Les workloads critiques (comme les bases de données) sont isolés au sein de chaque spoke.
Quelques conseils pratico-pratiques
- Automatisez au maximum. Déployez toute la partie segmentation réseau avec Terraform et Ansible pour gérer les configurations internes à chaque spoke.
- Faites des tests de résilience. Simulez des pannes du hub pour vous assurer que vos spokes peuvent continuer à fonctionner en mode dégradé.
- Optimisez vos flux réseau. Le problème de ce système, c'est que chez les GAFAM, vous avez un cout réseau non négligeable; Veillez à surveiller ça de près.
- Équilibrez centralisation et autonomie. Ne centralisez que ce qui est absolument nécessaire pour éviter de créer des goulots d'étranglement.
Conclusion
Le pattern Hub-and-Spoke s'adapte bien aux infrastructures cloud public et cloud privé, mais ça demande une attention particulières aux dérives. Chaque cas d'usage est unique, et je dirais que sans maturité et une équipe autonome, c'est difficile à maintenir.
C'est un article assez théorique car difficile de résumer des choix d'architectures compréhensibles et applicables au plus grand nombre.